



IoT signaling storm prevention: causes, risks, and device-level best practices

Mikk Lemberg
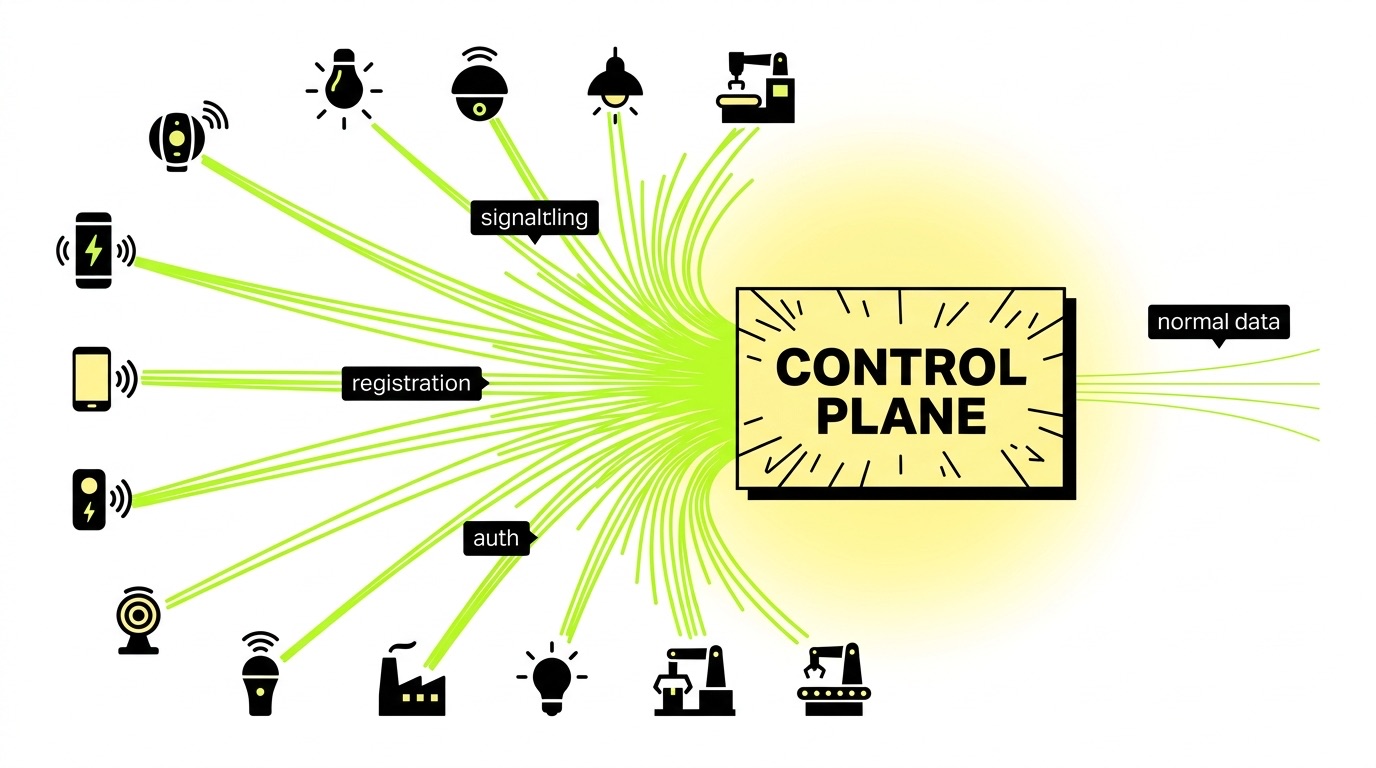
A single misconfigured retry loop across a fleet of 10,000 devices can cripple a cellular network's control plane. Signaling storms are one of the most underestimated risks in IoT deployment – and most originate not from the network, but from firmware decisions made during hardware design.
In this article
- What is an IoT signaling storm?
- What causes signaling storms in IoT deployments?
- The cascade effect: what happens when a storm hits
- Device-level best practices for OEMs
- How connectivity infrastructure affects storm risk
- Frequently asked questions
- Key takeaways
What is an IoT signaling storm?
A signaling storm occurs when a large number of devices simultaneously flood the cellular network's control plane with registration requests, session setup messages, or authentication retries – faster than the network can process them. Unlike data-plane congestion (too much payload traffic), signaling storms overwhelm the network's management functions: the AMF, SMF, and NRF nodes in 5G Core, or the MME in 4G LTE.
The result is a network that can't accept legitimate connections – not because it lacks bandwidth, but because it's buried in control messages. For OEMs shipping tens of thousands of devices, this distinction matters enormously. Understanding the elements of IoT connectivity – including how devices register, authenticate, and maintain sessions – is the foundation for understanding why storms happen and how to stop them.
What causes signaling storms in IoT deployments?
The triggers are almost always device-side, not network-side. Understanding the root causes is the first step toward preventing them.
Aggressive reconnection logic
The most common culprit we see in fleet deployments is firmware that retries a failed connection immediately and repeatedly. When a device loses signal, connects to a congested cell, or fails authentication, the logical firmware response is to try again – but without a backoff strategy, that retry loop becomes a denial-of-service attack at scale.
3GPP standards explicitly require devices to retry with increasing back-off periods and randomized timers. Yet many IoT devices in production don't follow this guidance. We've flagged this issue with OEM customers before shipment and found it regularly – it's rarely malicious, just unconsidered.
Synchronized mass reconnection
Power restoration events are particularly dangerous. When grid failures knock out mobile sites and power returns, millions of devices attempt to reconnect in near-perfect lockstep. An April 2024 grid collapse demonstrated exactly this: sites failed in sync with outages, and the subsequent reconnection wave left over half of subscribers without service. IoT fleets compound this problem because their firmware is often identical – every device reacts to the same trigger at the same time.

Misconfigured timers and APN settings
State mismatches between device and network occur when timers are misconfigured. A device that believes it's still registered while the network has expired its session will continuously generate re-registration attempts. Similarly, incorrect APN configuration or invalid PLMN IDs can cause continuous failed registration attempts as the device cycles through operators without finding a valid session.
Application-layer connection churn
Heartbeat mechanisms in messaging applications and IoT data protocols periodically establish and release connections, triggering frequent RRC (Radio Resource Control) state changes. Across a large fleet transmitting small, frequent payloads, this connection cycling generates a disproportionate volume of control-plane messages relative to actual data transferred. This is a particular risk for devices using NB-IoT or LTE-M with aggressive keep-alive intervals.
Firmware bugs and loop conditions
A documented case in the U.S. involved a misconfigured router that caused devices to continually attempt IMS re-registration over Wi-Fi when primary registration failed – creating a persistent rerouting loop that compounded network congestion. Firmware bugs that prevent proper state tracking are among the hardest to catch before large-scale deployment, and we've seen them surface only after a fleet crosses a certain density threshold in a single cell.
The cascade effect: what happens when a storm hits
Signaling overload doesn't fail gracefully. The consequences escalate quickly and tend to be self-reinforcing.
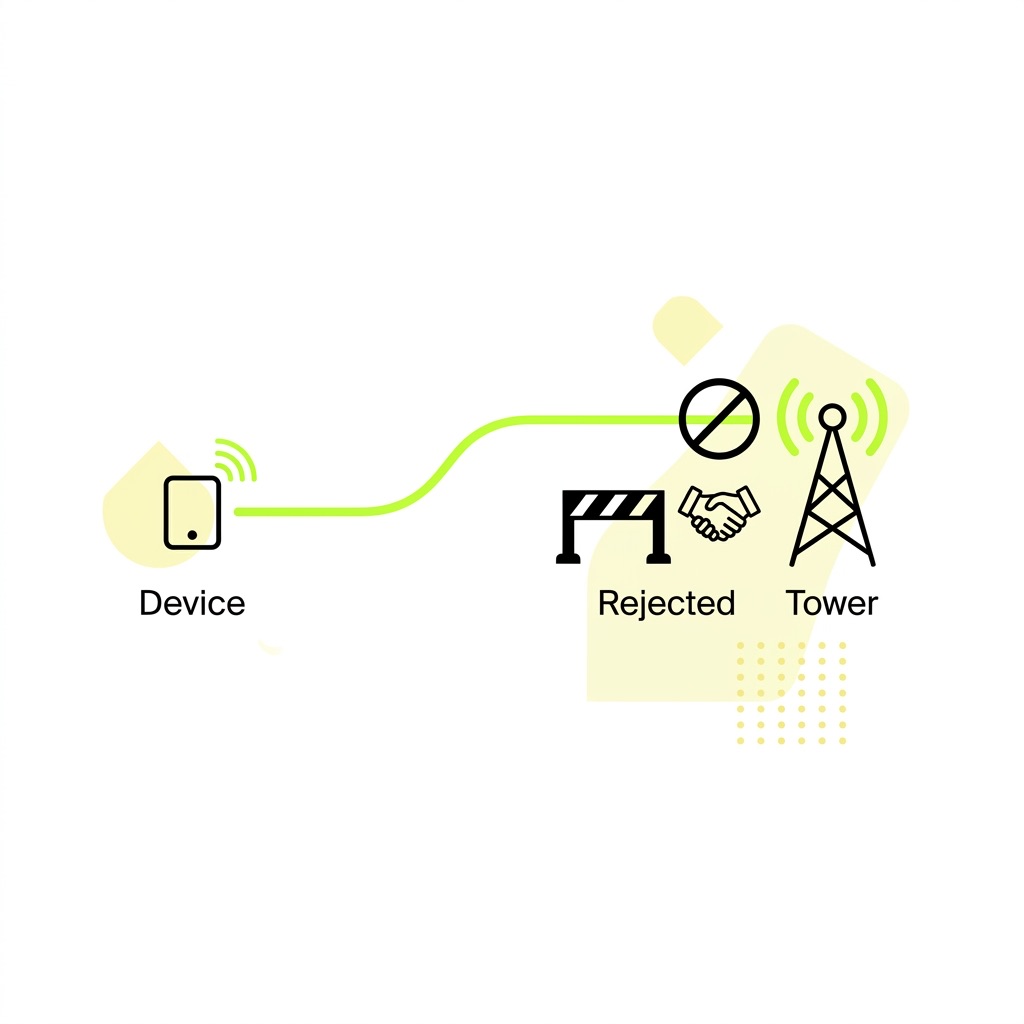
Failed connections trigger more retries, which generate more failures, which generate more retries. At the same time, devices that are behaving correctly get rejected because the network is processing malformed or looping requests from others. Increasing latency across authentication functions then affects all connected devices in the affected cell – not just the offending ones. The storm spreads the damage far beyond its source.
The point where fleet OEMs feel it most acutely is operator intervention. Carriers can temporarily block entire SIM pools or IMEI ranges from offending deployments, taking your entire fleet offline. We've seen situations where poorly behaved firmware on a subset of devices caused operators to flag the entire SIM pool – an outcome that's both commercially damaging and extremely difficult to reverse quickly. Modern 5G Core architectures include the Network Data Analytics Function (NWDAF), which applies machine learning to telemetry from AMF and SMF to identify devices exceeding normal request rates. Operators can and do use this to isolate specific IMEI ranges or SIM pools. By the time they act, the window for self-remediation has usually closed.
Device-level best practices for OEMs
This is where prevention actually happens: in firmware, before deployment. Network-side mitigations exist, but they're remedies, not solutions.

Implement exponential backoff with jitter
- Start with a short retry interval (e.g., 2 seconds) and double it after each failed attempt: 2s → 4s → 8s → 16s → up to a defined cap
- Add randomized jitter (±20–30%) to each interval so devices in the same fleet don't synchronize their retries
- Define a maximum retry count before entering a long dormancy period (e.g., 30–60 minutes) rather than looping indefinitely
Use power-saving modes correctly
- Configure PSM (Power Saving Mode) and eDRX (Extended Discontinuous Reception) parameters appropriate to your use case – these reduce unnecessary connection cycling
- Avoid frequent application-driven reboots of the cellular module, which generate unnecessary attach/detach sequences and increase load on network servers
- For LTE-M deployments, test PSM, eDRX, and combined configurations separately before committing to production settings; for NB-IoT devices, verify that your module's fallback radio behavior doesn't introduce additional registration cycles
Validate timer configurations
- Ensure T3412 (periodic TAU timer) and T3324 (active timer) values are aligned between device and network expectations
- Avoid default timer values from module manufacturers without verifying they match your operator's configuration – mismatches are a primary cause of state-loop signaling
Limit connection setup frequency at the application layer
- Batch telemetry payloads rather than sending each reading as a separate session
- Use persistent connections (e.g., MQTT over a long-lived TCP session) rather than opening and closing sessions per transmission
- Review AT command configurations for your module to verify Fast Dormancy settings align with GSMA TS.18 recommendations
Stagger initialization on power-up
- Build randomized startup delays into firmware so devices don't all attempt registration simultaneously after a power event
- For large fleet deployments, consider grouping devices into registration cohorts with different startup windows
How connectivity infrastructure affects storm risk
Firmware is the primary lever, but your connectivity provider's infrastructure either amplifies or dampens your exposure.
Multi-network access as a safety valve
When one network is congested, devices on a multi-network connectivity platform can switch to an alternative operator rather than hammering the same congested cell with retries. This isn't just a coverage story – it's a storm mitigation mechanism. A device that finds a working network on the first or second attempt generates a fraction of the signaling load of one that cycles through failed attempts on a single network.
Steered SIMs that force devices back to a preferred network compound this problem by generating additional registration signaling every time the device moves or loses connection. Non-steered SIMs allow the device to connect to the strongest available network, reducing unnecessary re-registration cycles from the outset.
eSIM profile switching as a recovery mechanism
If a carrier network experiences a signaling-related outage or begins blocking SIM pools from a congested deployment, eSIM profile switching allows affected devices to move to an alternative carrier profile over the air – without physical intervention. This is particularly valuable during operator-side remediation events that can take hours or days to resolve. The ability to switch profiles remotely means your fleet isn't hostage to a single carrier's recovery timeline.
Visibility during incidents
When a storm does occur, the ability to identify which devices are generating abnormal signaling, suspend specific SIMs, and monitor reconnection behavior in real time is what separates a contained incident from a prolonged outage. Connectivity management platforms that provide session-level telemetry – not just aggregate usage – give OEMs the operational control to respond before carriers take broader action. If your platform can't show you which SIMs are generating abnormal control-plane activity, you'll find out about a signaling problem from your carrier, not from your dashboard.
Frequently asked questions
What is the difference between a signaling storm and network congestion?
Network congestion is a data-plane problem: too much payload traffic for available bandwidth. A signaling storm is a control-plane problem – too many connection management messages (registrations, authentications, session setups) overwhelming the network functions that process them. A network can have spare data capacity and still fail to accept new connections during a signaling storm. The two can occur together, but they have different causes and require different remedies.
How do I know if my firmware is causing signaling issues before deployment?
Test under simulated failure conditions: cut network connectivity to a test batch of devices and observe how they behave on restoration. Count attach requests per device over a 60-minute recovery window and compare against GSMA guidelines for acceptable retry behavior. Any device generating more than a few hundred attach requests per hour under failure conditions warrants firmware review. We recommend doing this before production sign-off, not after – catching it post-deployment is considerably more expensive.
Can operators detect which devices are causing a signaling storm?
Yes. Modern 5G Core architectures include the Network Data Analytics Function (NWDAF), which applies machine learning to telemetry from AMF and SMF to identify devices exceeding normal request rates and detect looping message sequences. Operators can and do use this to isolate and block specific IMEI ranges or SIM pools – which is why OEM-side prevention is far preferable to waiting for operator intervention.
Key takeaways
- Signaling storms are a firmware problem first. Aggressive retry logic, missing backoff, and misconfigured timers are responsible for the majority of storm events – and all are preventable before deployment.
- Exponential backoff with randomized jitter is non-negotiable for any fleet of devices that might experience simultaneous failure events – power outages, network outages, or mass reboots.
- Multi-network connectivity reduces storm risk by giving devices an alternative path rather than forcing repeated retries against a single congested or unavailable network.
- eSIM profile switching provides a recovery mechanism when operator-side blocking or carrier-level incidents take a single network out of reach for your devices.
- Visibility is your early warning system. If your connectivity platform can't show you which SIMs are generating abnormal control-plane activity in real time, you'll find out about a signaling problem from your carrier – not from your dashboard.
Building a connected product that behaves well at scale requires getting the firmware right before you ship. If you're working through a deployment and want a second opinion on your module configuration or connectivity setup, talk to the 1oT team – we've seen enough of these issues to know where the problems usually hide.




























.avif)










